OpenClaw en mode vocal — STT local + Edge TTS (Microsoft)
Pipeline vocal OpenClaw : STT local avec whisper.cpp, TTS via Edge TTS Microsoft. Fonctionnel sans clé API, mais pas entièrement local.
Partie 6 de la série OpenClaw — Comment parler à son agent IA en self-hosted via Telegram, avec whisper.cpp pour la transcription et Edge TTS pour la synthèse.
Note (mise à jour mars 2026) : Cet article décrit un pipeline partiellement local. Le STT (whisper.cpp) tourne bien en local sur votre machine. Le TTS en revanche — Edge TTS — passe par les serveurs Microsoft Azure Speech à chaque appel, même sans clé API. Si vous cherchez un pipeline 100% local et zéro cloud, lisez l’article suivant sur Kokoro + speaches GPU qui couvre justement ça.
Mon stack OpenClaw tourne sur une VM Ubuntu, dans un container Docker, avec Ollama comme backend LLM local et Telegram comme interface principale. Tout est self-hosted, tout est local.
La question naturelle après quelques semaines d’utilisation : peut-on interagir par la voix ?
Envoyer un vocal sur Telegram, que l’agent comprenne, réponde — et idéalement réponde aussi en audio. Sans passer par OpenAI Whisper API, sans ElevenLabs, sans aucune clé externe.
Spoiler : c’est possible.
Architecture finale
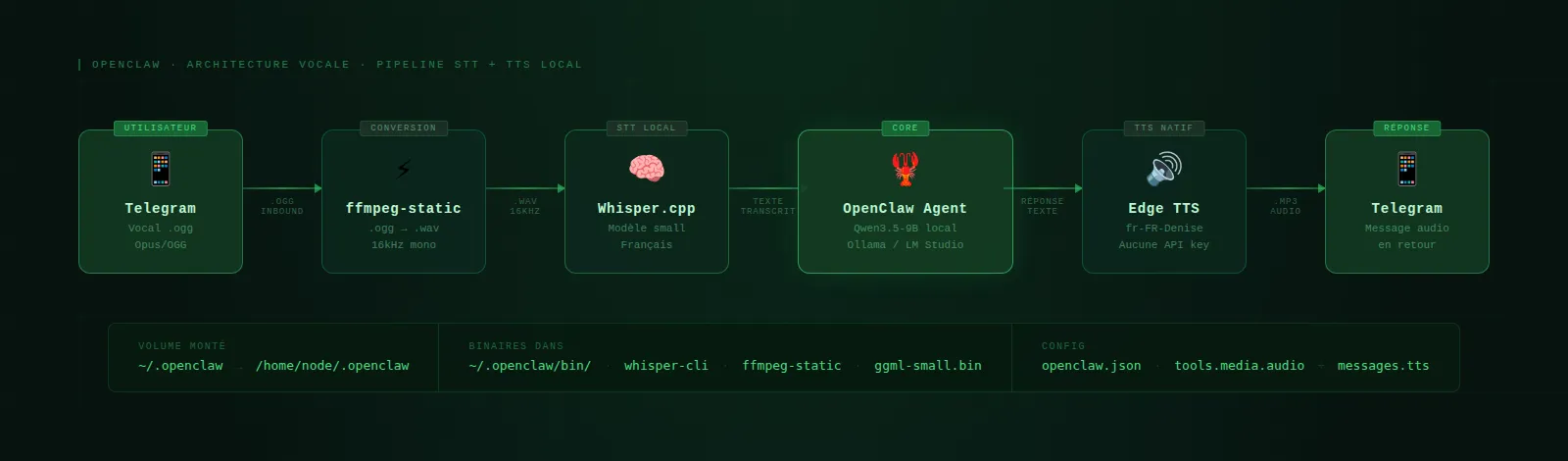
🎤 Vocal Telegram
↓
ffmpeg-static ← conversion .ogg → .wav
↓
whisper-cli ← transcription locale (whisper.cpp)
↓
OpenClaw Gateway ← agent turn sur le modèle local
↓
Edge TTS (natif) ← synthèse vocale, aucune API key
↓
🔊 Réponse audio TelegramTout roule dans le container Docker d’OpenClaw, via le volume ~/.openclaw déjà monté.
Étape 1 — Compiler whisper.cpp sur le host
whisper.cpp est un binaire C++ natif — zéro dépendance Python, zéro modèle PyTorch. On le compile sur le host Ubuntu, puis on l’expose dans le container via le volume ~/.openclaw.
sudo apt install -y cmake build-essential git
cd ~
git clone https://github.com/ggerganov/whisper.cpp
cd whisper.cpp
cmake -B build
cmake --build build -j$(nproc)
# Modèle small (465 MB, bon compromis précision/vitesse)
bash models/download-ggml-model.sh smallVérifie que ça fonctionne :
./build/bin/whisper-cli \
-m models/ggml-small.bin \
-l fr -nt \
samples/jfk.wav 2>/dev/nullTu dois voir la transcription du discours JFK.
Étape 2 — Copier les binaires dans ~/.openclaw/bin
mkdir -p ~/.openclaw/bin
# whisper-cli + libs
cp ~/whisper.cpp/build/bin/whisper-cli ~/.openclaw/bin/
cp ~/whisper.cpp/build/src/libwhisper.so.1 ~/.openclaw/bin/
cp ~/whisper.cpp/build/ggml/src/libggml.so ~/.openclaw/bin/
cp ~/whisper.cpp/build/ggml/src/libggml-base.so ~/.openclaw/bin/
cp ~/whisper.cpp/build/ggml/src/libggml-cpu.so ~/.openclaw/bin/
# Symlinks nécessaires
cd ~/.openclaw/bin
ln -sf libggml.so libggml.so.0
ln -sf libggml-base.so libggml-base.so.0
ln -sf libggml-cpu.so libggml-cpu.so.0
# Modèle
cp ~/whisper.cpp/models/ggml-small.bin ~/.openclaw/bin/Étape 3 — ffmpeg statique
Telegram envoie les vocaux en .ogg (opus). whisper-cli n’accepte que .wav. Le ffmpeg Ubuntu est compilé avec des dizaines de libs absentes du container Alpine — on prend donc le build statique officiel.
curl -L https://github.com/BtbN/FFmpeg-Builds/releases/download/latest/ffmpeg-master-latest-linux64-gpl.tar.xz \
-o /tmp/ffmpeg-static.tar.xz
tar -xf /tmp/ffmpeg-static.tar.xz -C /tmp/
cp /tmp/ffmpeg-master-latest-linux64-gpl/bin/ffmpeg ~/.openclaw/bin/ffmpeg-static
chmod +x ~/.openclaw/bin/ffmpeg-staticTest dans le container :
docker exec openclaw-openclaw-gateway-1 \
/home/node/.openclaw/bin/ffmpeg-static -version 2>&1 | head -1Étape 4 — Le wrapper whisper
OpenClaw appelle le CLI avec ses propres arguments. Le wrapper doit convertir .ogg → .wav avant de passer à whisper-cli.
cat > ~/.openclaw/bin/whisper << 'EOF'
#!/bin/sh
export LD_LIBRARY_PATH=/home/node/.openclaw/bin
TMP="/tmp/whisper_$$.wav"
INPUT=""
for arg; do INPUT="$arg"; done
ARGS=""
for arg; do
if [ "$arg" != "$INPUT" ]; then
ARGS="$ARGS $arg"
fi
done
/home/node/.openclaw/bin/ffmpeg-static \
-i "$INPUT" -ar 16000 -ac 1 "$TMP" -y 2>/dev/null
/home/node/.openclaw/bin/whisper-cli $ARGS "$TMP" 2>/dev/null
rm -f "$TMP"
EOF
chmod +x ~/.openclaw/bin/whisperÉtape 5 — Configurer le STT dans openclaw.json
python3 -c "
import json
with open('/home/rogmini/.openclaw/openclaw.json') as f:
config = json.load(f)
config['tools']['media'] = {
'audio': {
'enabled': True,
'models': [{
'type': 'cli',
'command': '/home/node/.openclaw/bin/whisper',
'args': [
'-m', '/home/node/.openclaw/bin/ggml-small.bin',
'-l', 'fr', '-nt', '{{MediaPath}}'
],
'timeoutSeconds': 60
}]
}
}
with open('/home/rogmini/.openclaw/openclaw.json', 'w') as f:
json.dump(config, f, indent=2)
print('OK')
"{{MediaPath}} est un template OpenClaw — remplacé automatiquement par le chemin du fichier audio.
Étape 6 — Configurer le TTS
OpenClaw intègre nativement Edge TTS de Microsoft — gratuit, sans clé API, voix neurales de qualité. C’est le provider le plus simple à configurer pour démarrer.
Important : Edge TTS n’est pas local. Chaque synthèse vocale envoie le texte aux serveurs Microsoft Azure Speech via internet. Il n’y a pas de clé API à gérer, mais vos données transitent par Microsoft. Pour un TTS véritablement local (Kokoro sur GPU, via speaches), voir l’article suivant de la série.
auto: "inbound"déclenche les réponses audio uniquement quand l’entrée est aussi audio.
python3 -c "
import json
with open('/home/rogmini/.openclaw/openclaw.json') as f:
config = json.load(f)
config['messages']['tts'] = {
'auto': 'inbound',
'provider': 'edge',
'edge': {
'enabled': True,
'voice': 'fr-FR-DeniseNeural',
'lang': 'fr-FR',
'outputFormat': 'audio-24khz-48kbitrate-mono-mp3'
}
}
with open('/home/rogmini/.openclaw/openclaw.json', 'w') as f:
json.dump(config, f, indent=2)
print('OK')
"Étape 7 — Redémarre et teste
cd ~/openclaw && docker compose restartEnvoie un vocal sur Telegram. Tu reçois une réponse audio.
Points d’attention
Le JSON d’OpenClaw est strict — valide avant de redémarrer :
python3 -c "import json; json.load(open('/home/rogmini/.openclaw/openclaw.json')); print('OK')"whisper-cli ne lit pas le .ogg nativement malgré ce que dit la doc — la conversion ffmpeg est obligatoire pour les vocaux Telegram (format opus/ogg).
Le container Alpine n’a pas pip — la solution avec le binaire statique + volume monté évite complètement ce problème.
auto: "inbound" est crucial — sans lui, l’agent répond en audio à tous les messages texte aussi.
Résultat
Toi (vocal Telegram) : "Bonjour, comment ça va ?"
Agent (audio Telegram) : "Bonjour ! Ça va bien, merci.
Je suis prêt — qu'est-ce qu'on fait aujourd'hui ?"Latence totale : ~8-12 secondes sur CPU (transcription ~3s + inférence ~5s + TTS ~1s).
Ce qui vient ensuite
Ce pipeline est fonctionnel, mais pas entièrement local. Edge TTS passe par Microsoft. La prochaine étape naturelle est de remplacer cette dépendance par un TTS qui tourne sur votre propre matériel.
L’article suivant couvre exactement ça : Kokoro + speaches sur GPU via Tailscale — STT et TTS 100% sur votre hardware, zéro requête externe. Le prix à payer : quelques heures de debug et un proxy Python de 50 lignes.
- Upgrade vers le modèle
mediumpour une meilleure précision en français - VAD (Voice Activity Detection) pour couper le silence automatiquement
- Interface Pipecat pour une boucle vocale temps réel depuis le navigateur
Partager cet article